During the last period, I’ve been interacting on a daily basis with Large Language Models (LLMs), especially ones from OpenAI, more precisely the ones provided by Azure. During that period, I faced some -fairly challenging- challenges, learned many lessons, which I’ll be sharing in this article.
Monitor your costs 💰
I know, that’s FinOps 101, always have your costs limited and monitored. In our case we were very invested in showing tangible results, were using models without checking if they are expensive or not, we took costs for granted since the models presented in the Azure OpenAI’s pricing page were fairly cheap ($0.002 for gpt-3.5-turbo, $0.0001 for ada embeddings). But after several weeks, we got a fat invoice from Azure of more than 10k$, the weird part was that 90% of the bill consisted of embedding costs, which didn’t make sense (unless we were embedding the bible).
When debugging, we had several possible explanations in mind, presented -in order- in the following list:
We had some code issues: maybe we were doing some looping over documents, or there were some recursive calls which accumulated costs. But after checking the git history, the embedding logic didn’t change that much, the only loops we uses were to iterate over files, and going over text splits to embed them. Other than that the rest of the pipeline was simple, therefore this possibility was discarded.
We were embedding very large documents: We suspected that some of the files we were using were large, this was easily discarded by checking the total size of documents. We were sure that it was not caused by the documents themselves.
There was a problem with Azure price calculations: After discarding issues from our side (at least ones we controlled directly), we started thinking that Azure miscalculated the costs (sounds crazy, right!). This possibility was (unfortunately) our last resort after discarding previous ones; before finding out that we were using a deprecated and very expensive embedding model.
The real reason: Using “bad” models: We were using
text-search-davinci-doc-001as embedding model, which was not only deprecated but also very expensive, and legacy models were not included in the Azure OpenAI pricing documentation, but were still available for use with no form of warning about deprecation. After few searches, we found out that the embeddingdavincimodel costs 2000 times (image below) more than theadamodel, which was the cheapest and the only one documented in Azure’s pricing pages. To illustrate this difference in pricing: the cost of embedding 1k tokens using thedavincimodel, can be used to embed 2 million tokens with theadamodel instead, which is roughly equal to 1.5 million words (1 word ≈ 1.33 token), which is similar to embedding the entire Lord of the Rings series (including The Hobbit) 2.5 times, which was not the intended use case for our product.
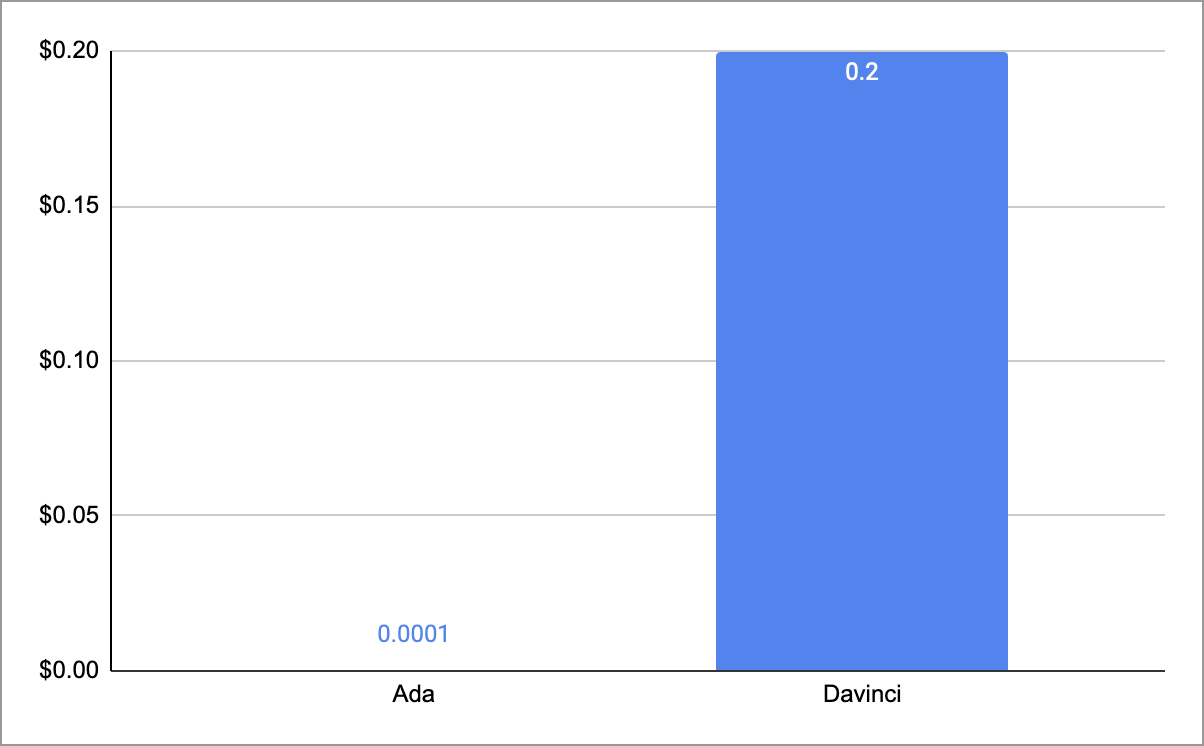
Cost comparison between ada and davinci models (price per 1k token)
After finding out the real reason, we made sure that all LLM related projects on Azure were using the ada model as embedding model (or at least avoiding davinci models).
Evaluate your LLMs 🔁
You can’t improve what you don’t measure - Peter Drucker
While developing LLM-based products, one might forget to create a feedback loop, at first all we did was trying to look at the data we feed to the LLM, prepare 2 or 3 main questions around the data, and keep asking the LLM on each prompt/code change, then assess (manually) how those changes affect the LLM’s output. To keep track of results, we made an Excel spreadsheet with a set of questions and their optimal answers (base truth), and started flushing LLM answers from each prompt version, with some color coding (🟥 red for bad answer, 🟩 green for good answer and 🟨 yellow for 50-50) and some comments on answers.
At one point, one needs to automate some of the manual work. For this specific problem, there are tools that do “prompt testing” (promptfoo, ChainForge …), which is a part of a new practice called LLMOps. These tools do the same thing we did using the spreadsheet, but automate it using more “powerful” LLMs (generally GPT-4) to do the color coding task and judge the correctness of answers, or simply compare the provided base truth answers with the LLM’s answers.
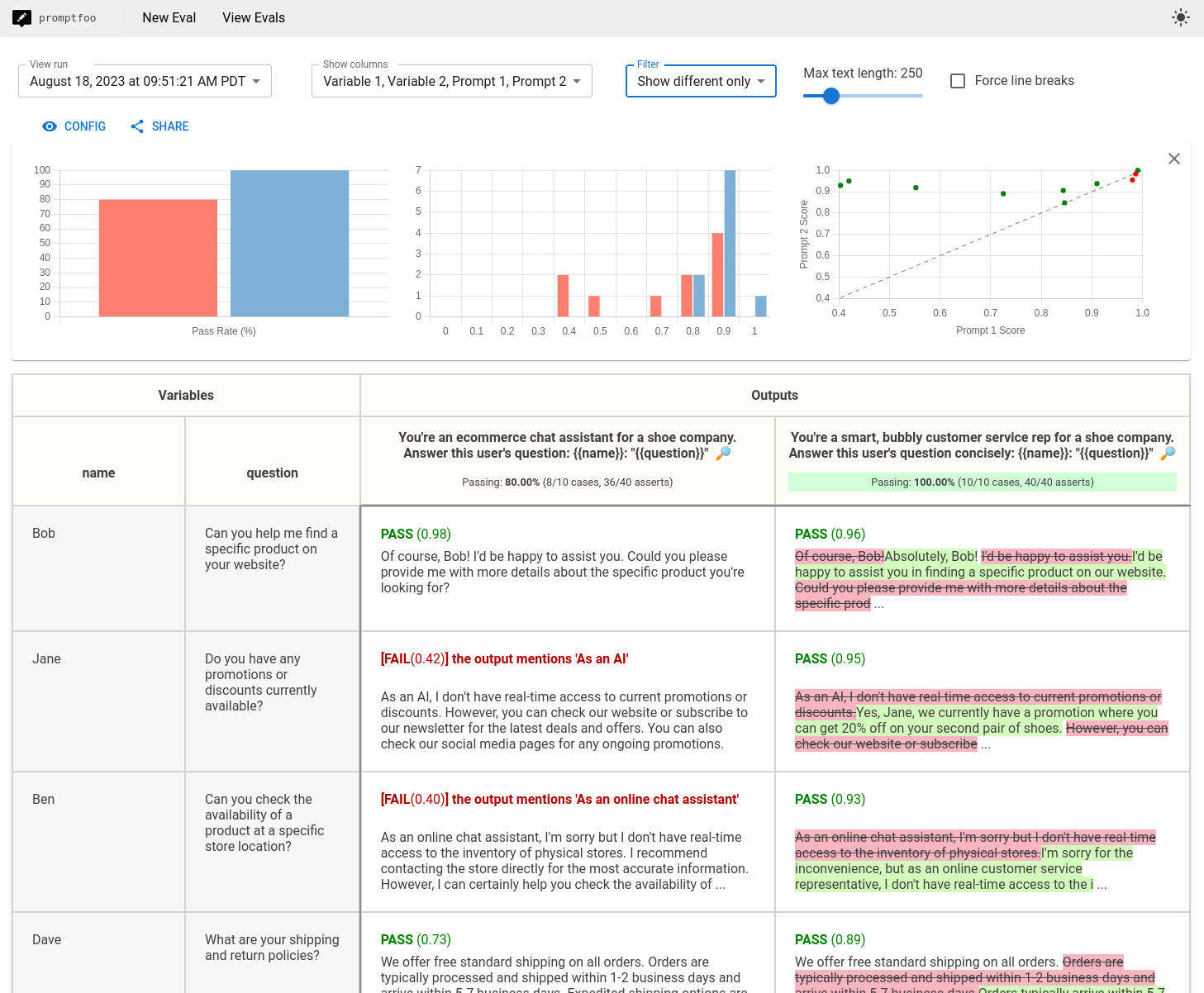
promptfoo Web UI
Chroma vs FAISS 🔎
When looking up available vector databases to use in the context of LLMs, the most popular open-source vectorstores were Chroma and FAISS. After some quick benchmarking on document similarity, and some setup issues with Chroma, we went with FAISS.
While working on the code, we were discovering some particularities in FAISS, the main one was that FAISS had some neural net or KNN mechanism to help out in document similarity calculation. We discovered this after trying to add new documents to the already existing ones, which wasn’t possible (at least back then).
Don’t overload the prompt 🤯
When playing with prompts, we were focusing on getting the bot to answer to the business-related questions, but we didn’t care that much about simple user input like greetings, or very vague questions. For example after deploying the first version, our first user started the conversation with the following question: How can you help me?. A question we were never expecting, and to which the bot answered with very random business-related keywords. We immediately started editing the prompt, by adding instructions to answer general user input with appropriate response.
After some testing, we found out that the bot wasn’t providing enough details, this also was added to the prompt. Afterward, we discovered that the bot would invent answers out of it’s “imagination”…
This rabbit hole of prompt modifications and adding instructions, ended up with a 1600 letter prompt, that limited the LLM’s context window (gpt-35-turbo has a 4096 token context window) and added more incoherence to answers, and started to look like an if-else instructed bot that works perfectly on some kind of input, and hallucinate otherwise.

LLM Context Window
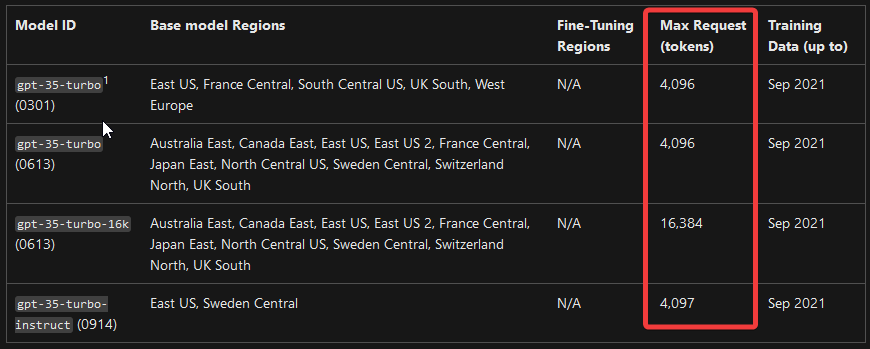
gpt-35 model family context window
When checking out similar, better performing, open-source products, we noticed that the prompts are not as complex as we made ours. Generally, there was a role initialization You're a bot specialized in DOMAIN, then some light instructions, like: answer in the same language as input, use the provided context, say I don't know instead of inventing answers, and an optional formatting instruction when using Markdown as output. This made us rethink our prompt and make it simpler and lighter, which improved the answers quality and correctness.
For more details about writing good prompts, check out learnprompting.org.