TL;DR: bcrypt ignores any bytes after the first 72 bytes, this is due to bcrypt being based on the Blowfish cipher which has this limitation.
bcrypt has been a commonly used password hashing algorithm for decades, it’s slow by design, includes built-in salting, and has protected countless systems from brute-force attacks.
But despite its solid reputation, it also has a few hidden limitations worth knowing about.
Let’s take a look at this code:
import bcrypt
password_1 = b"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa1"
password_2 = b"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa2"
hashed_password1 = bcrypt.hashpw(password_1, bcrypt.gensalt())
if bcrypt.checkpw(password_2, hashed_password1):
print("Good password")
else:
print("Bad password")The code takes a string (as bytes) starting with 72 a’s and ending with 1, hashes it using bcrypt.hashpw, and then checks the same string ending with 2 this time against the hashed password.
The output should be Bad password, right ?
Let’s run the code, and see the output: bcrypt.checkpw returns True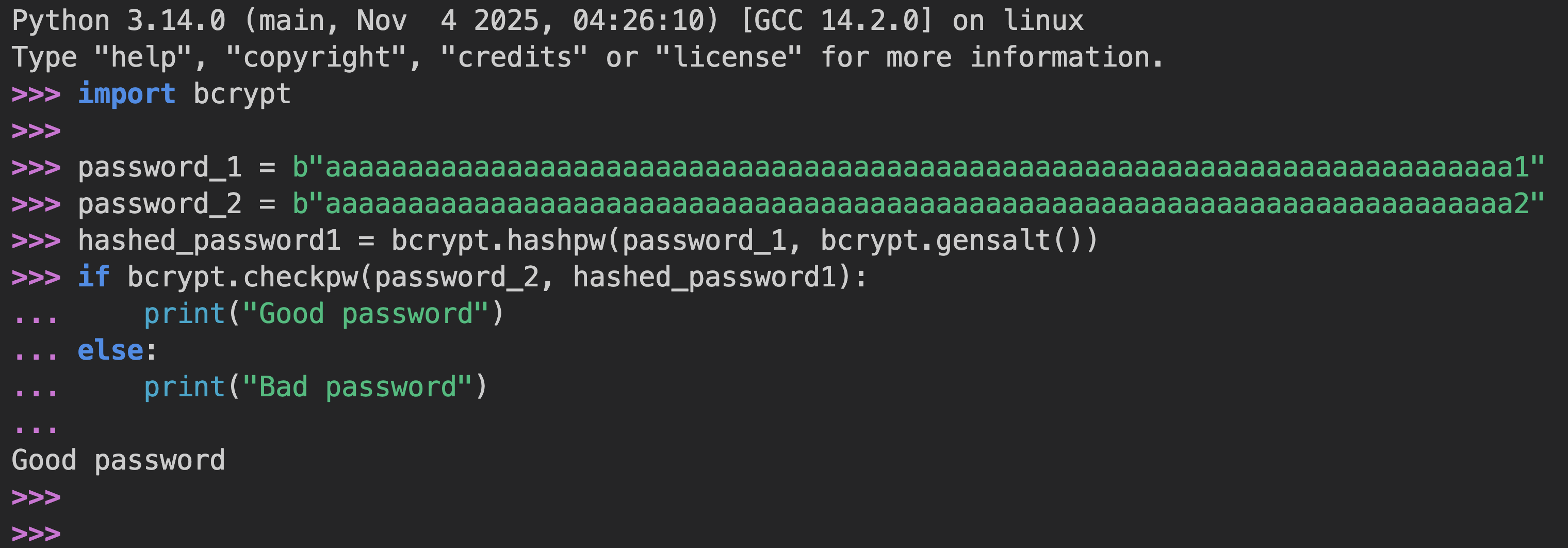
The code shows Good password, but why ????
Turns out that bcrypt is based on the Blowfish cipher, which only encrypts the first 72 bytes, this limitation is therefore inherited by bcrypt.
The Blowfish algorithm uses an 18-element P-box, where each element is a 32-bit (4-byte) subkey. Therefore, the total P-box size is 18 * 4 bytes (72 bytes).
This means that if the password is longer than 72 bytes, the bcrypt algorithm will only encrypt the first 72 bytes, and the rest will be ignored.
bcrypt’s 72-byte limit applies to bytes, not characters. This means that passwords with non-ASCII characters (like emojis or accented letters) may reach the limit even sooner, since UTF-8 encoding can use more than 1 byte per character.
If you don’t want to worry about this limitation, you have several alternatives:
Use a different algorithm, like Argon2, which does not have this limitation (Awarded the Password Hashing Competition in 2015).
Hash the password into a digest -less than 72 bytes- first (SHA-256, SHA-512, etc.), and then hash the digest using bcrypt. See the following example:
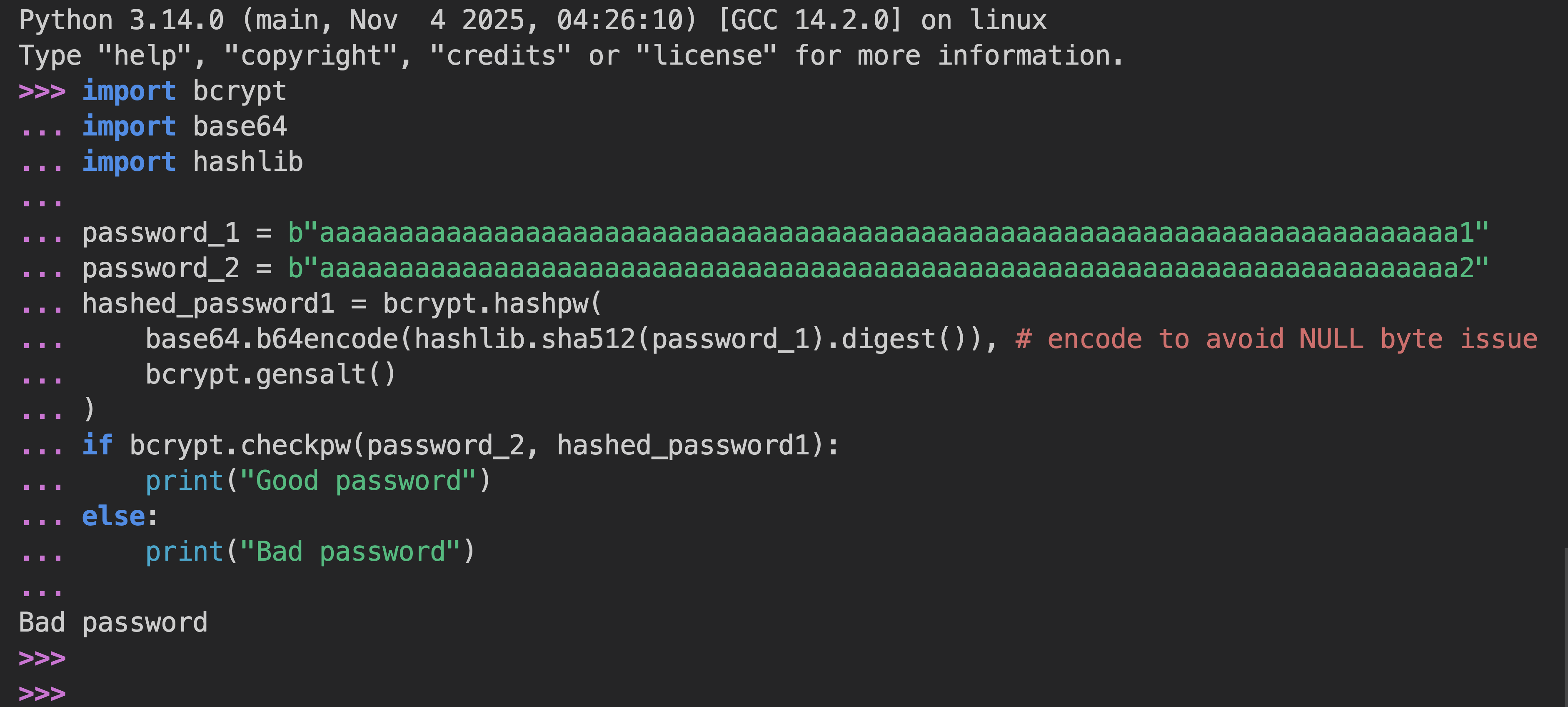
Hash with SHA-512 before bcrypt
- You can always enforce the password length to be less than or equal to 72 bytes by yourself, but it’s not recommended to do so.
However, since version 5.0.0, Python’s bcrypt package began raising errors when hashing passwords longer than 72 bytes, this commit introduces the change: Raise ValueError if password is longer than 72 bytes
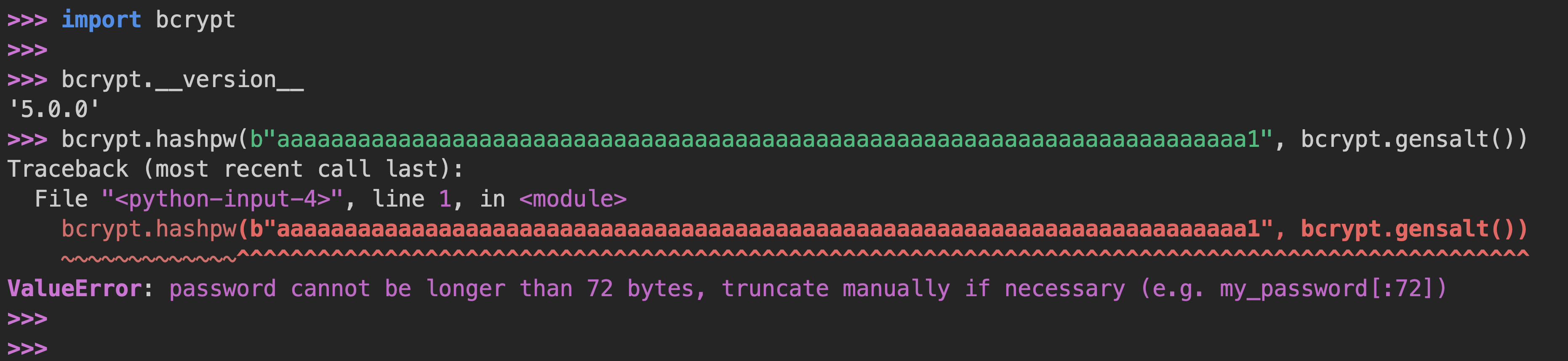
bcrypt.hashpw raises an error since version 5.0.0
This limitation is handled in different ways in other languages and libraries.
- Go raises an error when the password is longer than 72 bytes
- OpenBSD’s bcrypt implementation truncates the password if it’s longer than 72 bytes
- Rust’s bcrypt truncates the password by default, but offers
non_truncatingmethods to raiseBcryptError::Truncationerror if the password is longer than 72 bytes. - Spring Security’s base class
BCryptoffers the methodhashpwwithfor_checkflag (weird name, right ?) to raiseIllegalArgumentExceptioniffor_check = false, while I havent found a way to pass a similar flag to theBCryptPasswordEncoderclass.
In 2024, Okta -a major security service provider- had a security incident due to this limitation, they announced that the incident was caused by using bcrypt to hash cache keys for their AD/LDAP delegated authentication feature, which allowed attackers to use new usernames with old cached keys to authenticate to the service and gain access to user accounts.
To summarize, bcrypt is still fine for typical passwords <72 bytes, but consider other options for future-proof security.
I discovered this limitation in @devhammed’s tweet, thanks to him for sharing this information.